CNN(Convolutional Neural Networks)
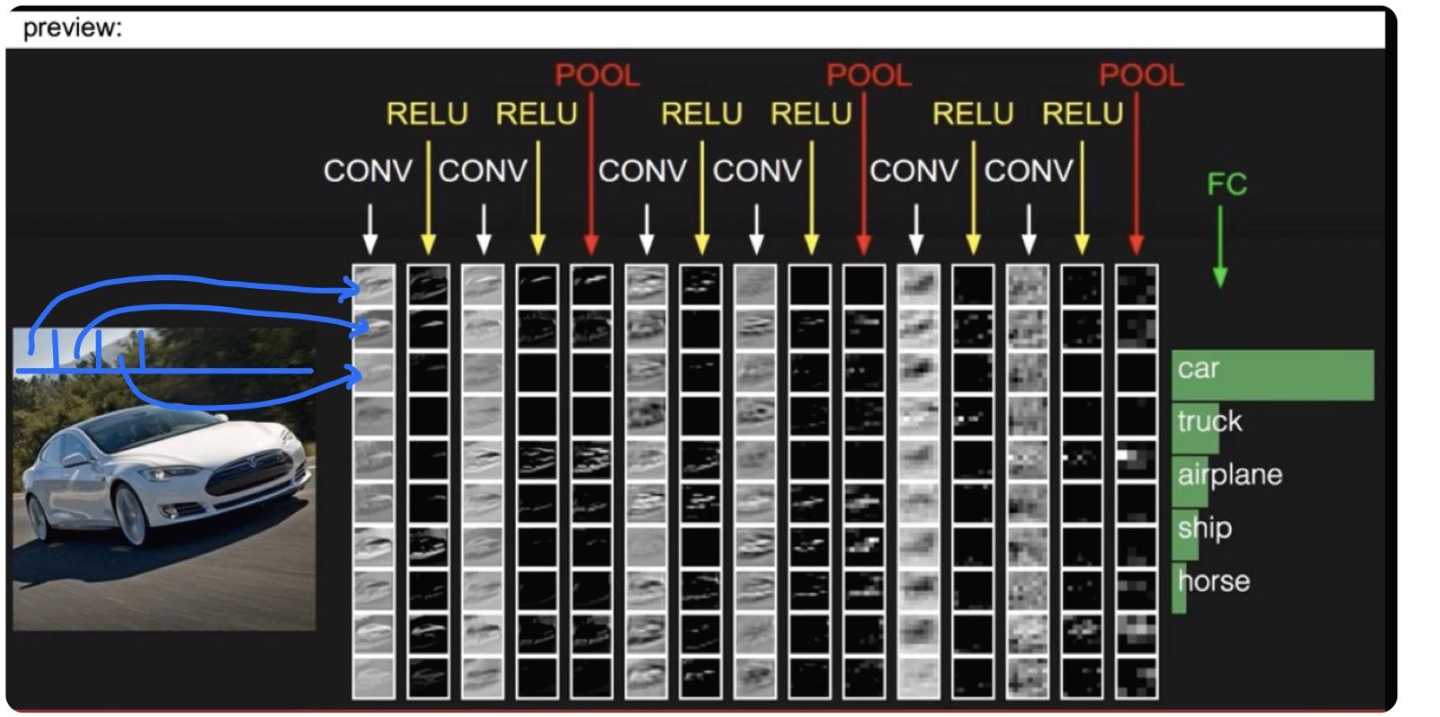
FC: Fully Connected Neural Network

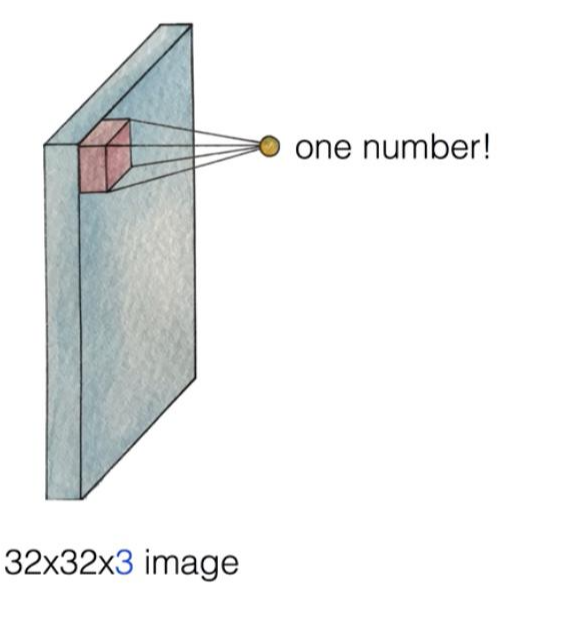
32x32x3 사이즈의 이미지를 5x5x3 사이즈의 필터로 쪼갭니다. 그러면 쪼갠 부분을 하나의 값으로 정합니다.
필터가 하는 일: 5x5 부분을 x로 정하고 x 부분에서 하나의 값을 뽑아냅니다.
one number를 어떻게 뽑아내는가?

$\bar{y} = w_1x+w_2x+w_3x+w_4x+...+b$
w(weight): one numer를 결정하는 요소가 됩니다.
How many numbers can we get?
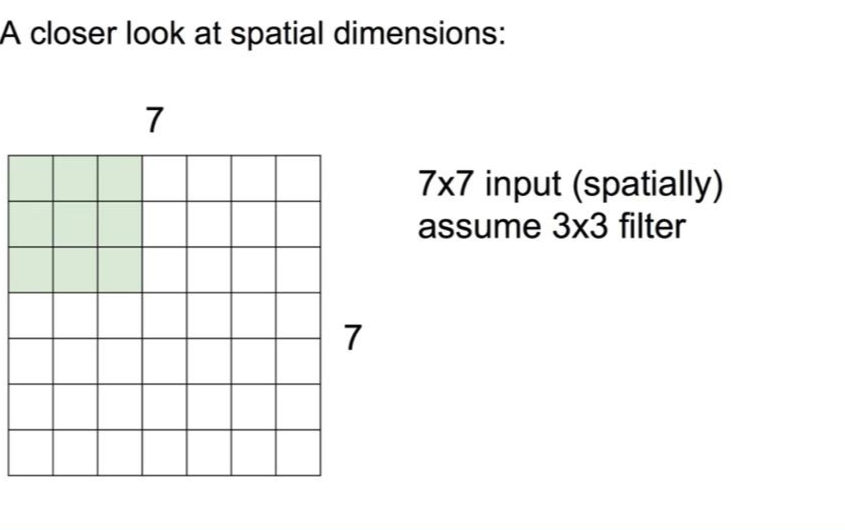
7x7 사이즈의 공간에서 3x3 사이즈의 필터로 값을 하나 골라냅니다. 그리고 필터를 옆으로 한 칸씩 이동하며 계속 값을 하나씩 골라냅니다. 옆으로 끝까지 이동한 후에는 아래로 한 칸씩 이동하며 같은 과정을 반복합니다. 이런 과정을 반복하게 되면 옆으로 5번, 아래로 5번 이동하게 되므로 출력의 값은 5x5가 될 것입니다.
stride(이동하는 크기): 1(칸)
output: 5x5
stride: 2
output: 3x3

stride에 큰 값을 줄수록 출력되는 이미지의 크기가 계속 작아집니다.
이를 방지하기 위해 pad를 사용합니다.
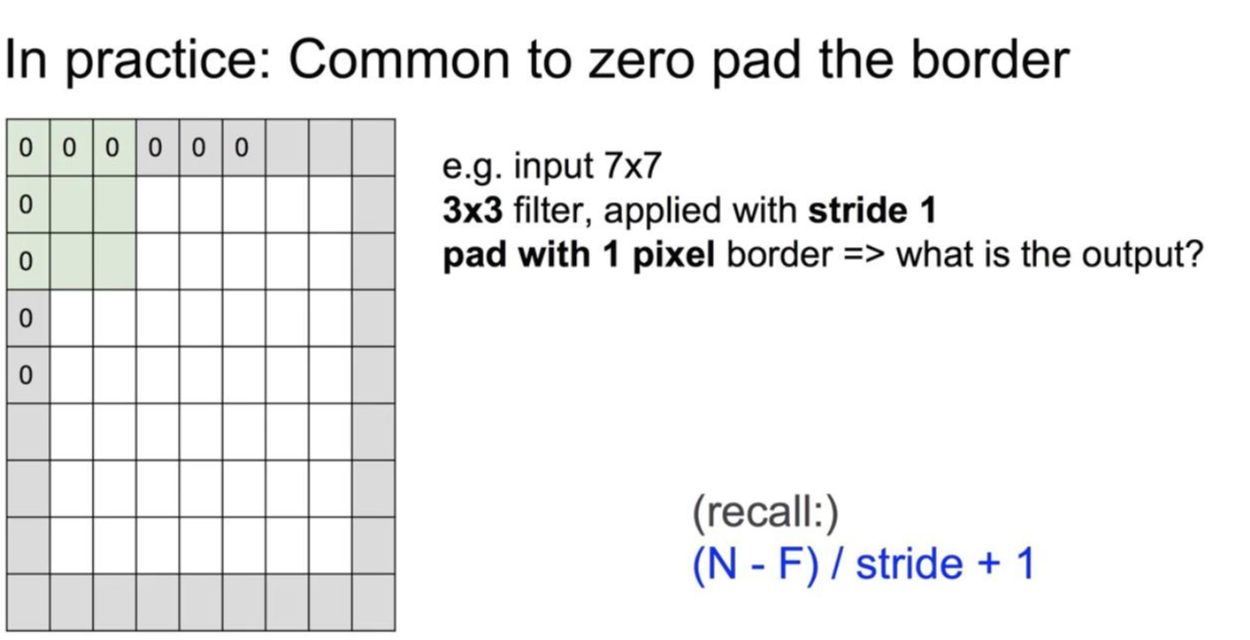
pad with 1 pixel: 1 pixel의 테두리 부분에 0이라는 값이 가상으로 있다고 만들어줍니다.
padding을 사용하는 이유
1. 이미지가 급격하게 작아지는 것을 방지하기 위해서 입니다.
2. 네트워크에 '이 부분이 모서리이다'라는 것을 알려주기 위해서 입니다.
padding을 사용한 output(input=7x7)
1. F=3 -> zero pad with 1
N=9, stride=1
output=(9-3)/1+1=7 ->7x7 output
2. F=5 -> zero pad with 2
N=11, stride=1
output=(11-5)/1+1=7 ->7x7 output
3. F=7 -> zero pad with 3
N=13, stride=1
output=(13-7)/1+1=7 ->7x7 output
input 7x7 -> 7x7 output
-in general, common to see CONV layers with stride 1, filers of size FxF, and zero padding with (F-1)/2/(will preserve size spatially)
-padding을 사용함으로써 입력과 출력의 결과가 동일해집니다.
Swiping the entire image
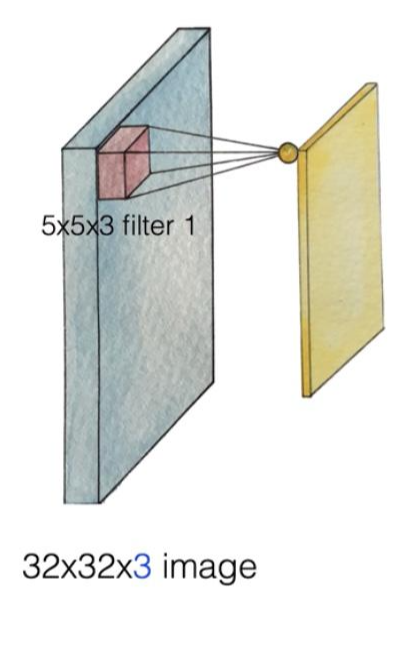

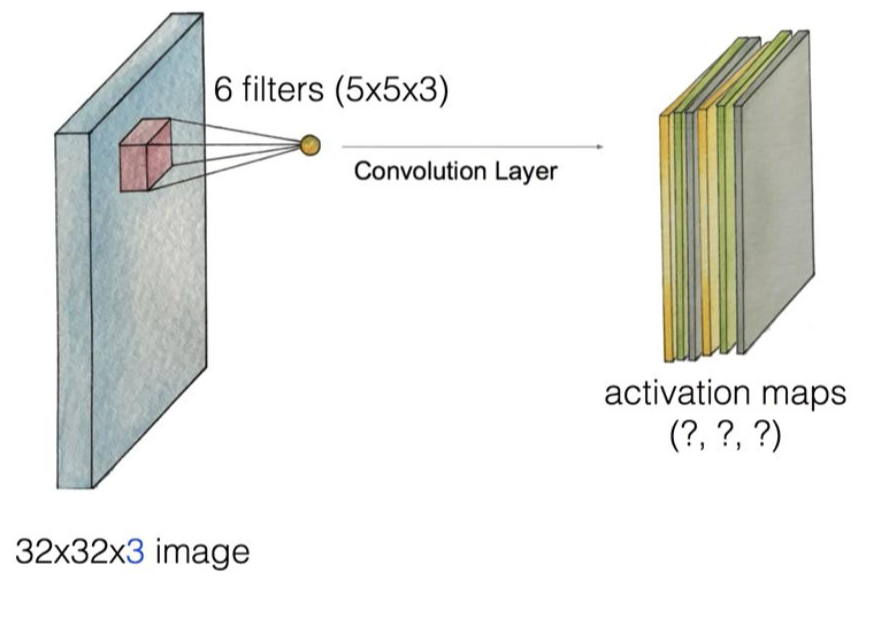
1. 첫번째 filter(filter1)를 이용해서 이미지를 하나 만듧니다.
2. 두번째 filter(filter2, 다른 weight set)를 이용해서 이미지를 하나 더 만듧니다.
3. 같은 방식으로 6개의 filter를 이용하면 각기 다른 6개의 이미지가 만들어지게 됩니다.
4. 최종 이미지의 깊이는 필터의 개수와 동일합니다: (?, ?, 6)
5. 앞의 두 값은 전체 이미지와 필터의 사이즈에 따라 결정됩니다: (28, 28, 6)-padding 하지 않은 경우
Convolution layers
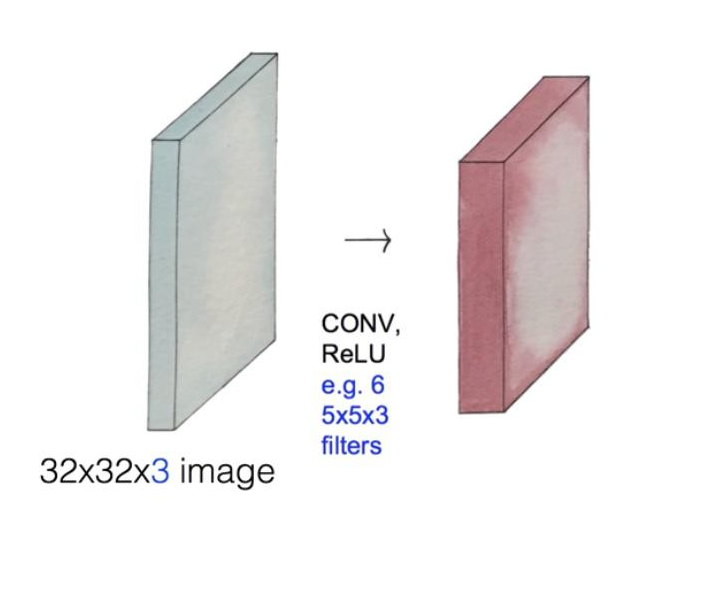

그림1. Activation Map: 앞의 과정을 여러 번 할 수 있습니다. CONV과 ReLU를 동시에 사용해서 적용할 경우 6개의 필터를 사용하므로 깊이가 6이 됩니다.
그림2. '그림1'의 과정을 여러 번 적용하여 그림1의 Activation Map에 Convolution Layer를 filter 10개로 적용합니다. 깊이는 필터의 개수인 10이 됩니다: (?, ?, 10)
How many weight variables?
그림1: 5x5x3x6
그림2: 5x5x6x10
How to set them?(이 값들이 어떻게 정해지는가?)
다른 neural network와 마찬가지로 처음에는 random한 방식으로 초기화를 합니다. 그 다음에는 가지고 있는 데이터로 학습을 하게 됩니다.
Pooling Layer(Sampling)
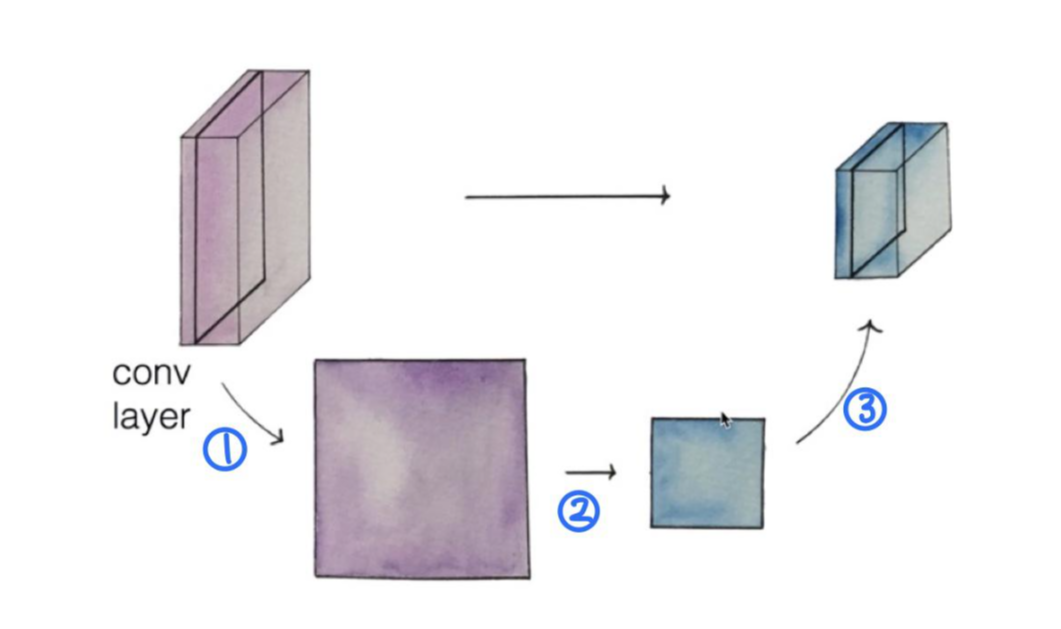
1. conv layer에서 한 layer를 뽑아냅니다.
2. pooling: 뽑아낸 layer를 resize(sampling)합니다.
3. pooling한 layer를 다시 쌓습니다.
Max Pooling
filter의 값들 중 가장 큰 값을 고르는 것입니다.

Fully Connected Layer(FC Layer)


1. Convolution의 결과로 나온 값을 ReLU라는 function에 입력합니다.
2. 중간중간에 Pooling 과정을 거치게 됩니다.(Pooling은 원하는 때에 넣어서 layer를 쌓을 수 있습니다.)
3. 우리가 원하는 대로 정한 과정에 따라 나온 전체 값을 x(입력)로 정하고, 원하는 만큼의 깊이를 정합니다.
4. 정한 깊이만큼 일반적인 neural network 과정을 진행합니다.
5. 마지막에 Softmax Classifier를 진행합니다.(10개, 100개 등 여러 개의 label 중 하나의 label을 정합니다.)
'인공지능' 카테고리의 다른 글
| [모두를 위한 딥러닝1] NN의 꽃 RNN 이야기(8주차) (0) | 2021.02.17 |
|---|---|
| [모두를 위한 딥러닝1] 여러가지 CNN 알고리즘(7주차_2) (0) | 2021.02.14 |
| [모두를 위한 딥러닝1] Weight의 초기값 설정하기(6주차_2) (0) | 2021.02.04 |
| [모두를 위한 딥러닝1] ReLU(6주차_1) (0) | 2021.02.04 |
| [모두를 위한 딥러닝1] 딥 네트워크 학습(5주차) (0) | 2021.01.27 |