
w 값을 0으로 설정하면 미분값도 0이 되므로 gradient 값이 사라지게 됩니다. 그러므로 w 값을 0으로 설정하면 안 된다는 것을 알 수 있습니다.

1. forward(encoder): x 데이터셋과 weight를 이용해서 출력값을 만들어냅니다.
2. backward(decoder): forward의 출력 결과와 forward에서 이용한 동일한 weight를 이용해서 거꾸로 값을 구합니다.
3. forward에서 이용한 x값과 2번에서 구한 x값을 비교합니다.
4. 두 x값의 차이가 최소가 되도록 weight 값을 조절합니다.
Deep Belief Network




1. 처음 두 layer를 가지고 forward와 backward 과정을 통해 만들어낼 수 있는 weight를 학습시킵니다.
2. 다음 두 layer를 가지고 동일한 과정을 거쳐서 만들어낼 수 있는 weight를 학습시킵니다.
3. 마지막 두 layer까지 동일한 과정을 거쳐서 학습을 완료합니다.
4. 학습이 완료된 전체 네트워크를 fine tuning(약간의 조정)을 통해 완성할 수 있습니다.
위의 과정을 통해 초기값을 잘못 주어서 나타나는 문제를 해결할 수 있습니다.

overfitting된 경우에는 일정 수준까지는 에러가 감소하다가 어느 수준이 넘어가면 에러가 다시 증가합니다.
Overfitting을 방지하기 위한 해결책
1. 많은 학습 데이터
2. Regularization
Regularization
1. cost + $\lambda\sum(w^2)$
2. Dropout


몇 개의 노드의 연결을 끊어버리는 것으로, 일부 노드들은 쉬게 한 다음 나머지 노드들을 이용해서 학습을 합니다. 그리고 마지막에 학습한 것들을 총동원해서 예측을 하는 방식입니다.
학습: 일부 노드만 사용
실제 모델을 사용할 때: 전체 노드를 사용
Ensemble

1. 각각 독립적인 Neural Network를 만듭니다.
2. 학습을 시킵니다.
3. 학습시킨 모델들을 합칩니다.
4. 합한 것을 바탕으로 예측을 진행합니다.
Fast Forward

1번의 출력을 두 layer 앞인 2번에 연결합니다. 또한 3번의 출력을 두 layer 앞인 4번에 연결합니다.
Split&Merge

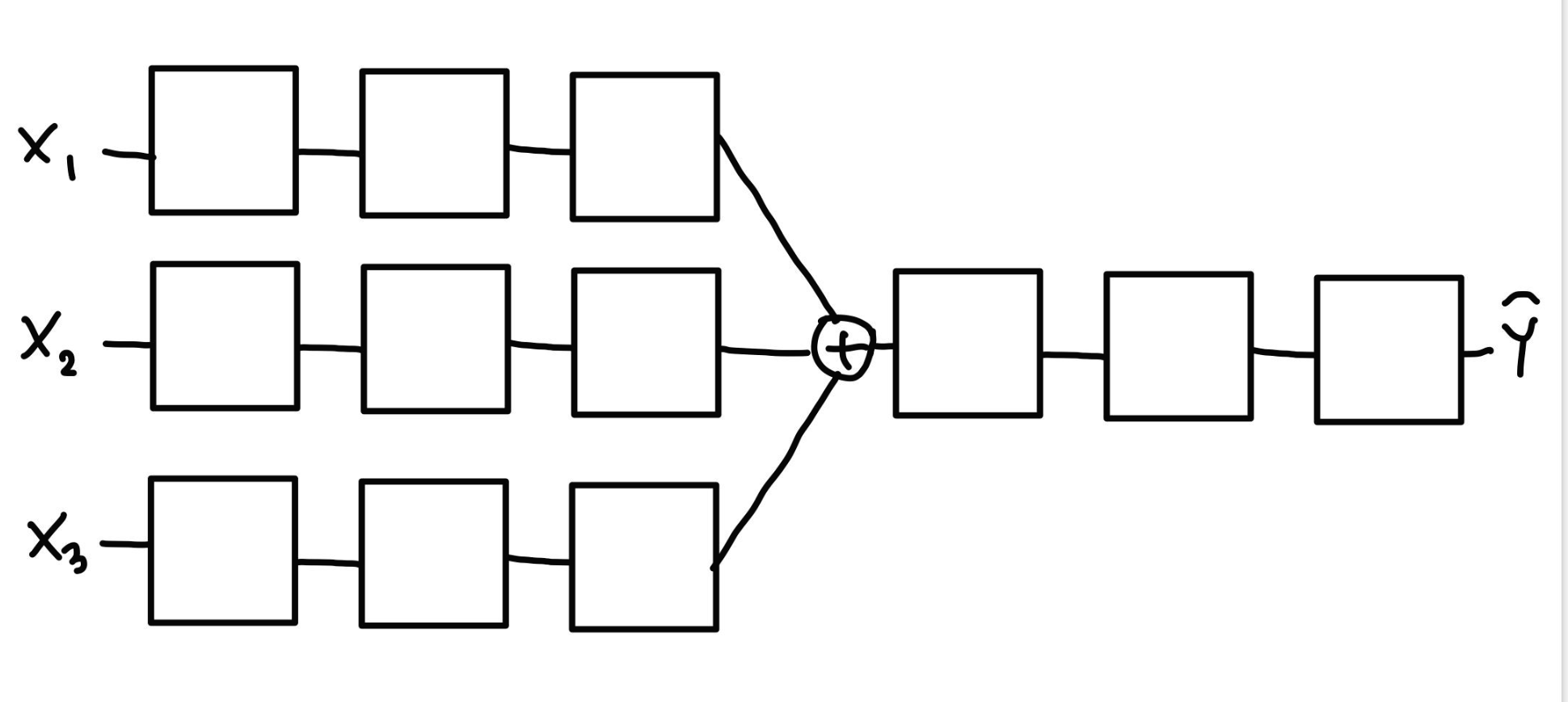
Recurrent Network

'인공지능' 카테고리의 다른 글
| [모두를 위한 딥러닝1] 여러가지 CNN 알고리즘(7주차_2) (0) | 2021.02.14 |
|---|---|
| [모두를 위한 딥러닝1] Convolutional Neural Networks(CNN)(7주차_1) (0) | 2021.02.14 |
| [모두를 위한 딥러닝1] ReLU(6주차_1) (0) | 2021.02.04 |
| [모두를 위한 딥러닝1] 딥 네트워크 학습(5주차) (0) | 2021.01.27 |
| [Tensor Manipulation] Stack & Ones and Zeros like &Zip (0) | 2021.01.23 |