LeNet-5
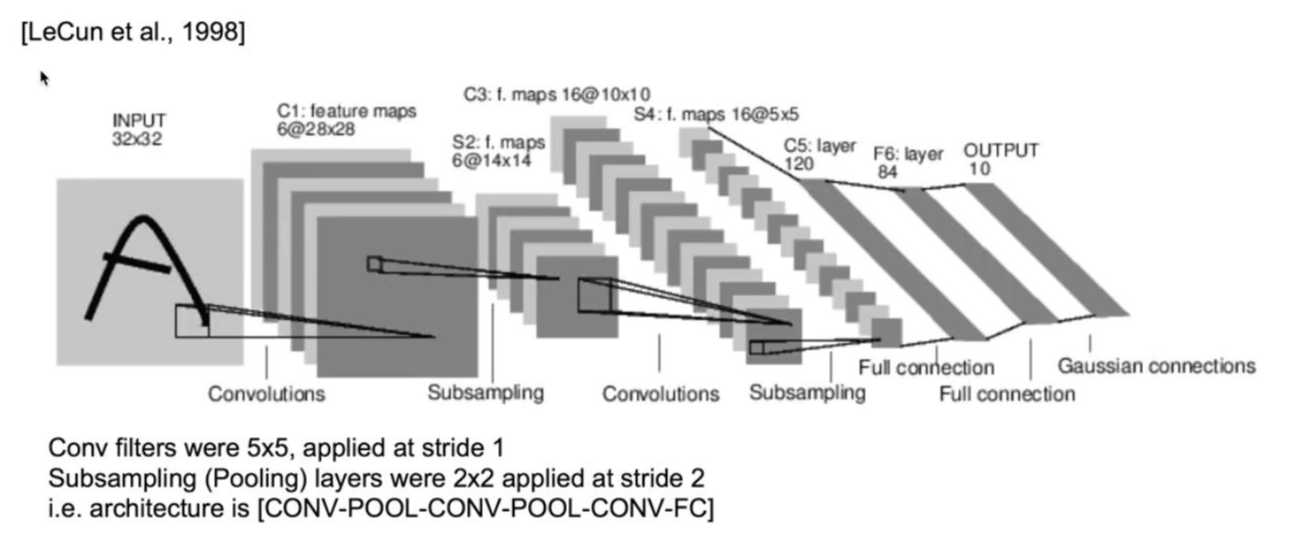
처음 Convolutions 과정에서 6개의 이미지를 만들어내고, 각각의 이미지를 Subsampling합니다. 해당 과정을 여러 번 반복하는 과정을 통해 output을 산출해냅니다.
AlexNet

첫번째 layer
227x227x3 이라는 매우 큰 사이즈의 이미지를 사용합니다. 필터는 11x11x3 사이즈 96개를 사용하며, stride는 4로 합니다.
96개의 필터를 사용했으므로 depth는 96이 됩니다. 그리고 사이즈 55x55의 이미지가 산출되므로 output은 55x55x96이 됩니다.

두번째 layer
3x3 사이즈의 필터를 사용하고, stride는 2로 합니다. output은 27x27x96이 됩니다.

여러 번의 layer를 거치는 과정을 나타내주고 있습니다.
CONV: convolution
MAX POOL: pooling
NORM: normalization(생략 가능)
마지막 pooling 과정(6x6x256 크기의 이미지를 3x3 필터와 stride 2로 pooling)을 거친 후 만들어 낸 출력값: 4096
FC: Fully Connected
output 값인 4096을 이용하여 FC 과정을 몇 번 거친 후, 마지막으로 4096개의 입력으로 1000개의 label을 만들어냅니다.

위의 AlexNet을 7개 합쳐서 오류를 15.4%까지 줄이게 되었습니다.
GoogLeNet

Inception module
레고를 쌓듯이 과정을 쌓아나가는 방식입니다.

1. 이전 layer를 받아와서 1x1 convolution 3개를 병렬로 나열합니다.
2. 3x3 pooling을 거쳐서 1x1 convolution을 하나 보내줍니다.
3. 1x1 convolution 위로 3x3 convolution과 5x5 convolution을 사용합니다.
4. 병렬로 나열된 것들을 모두 합쳐줍니다.
ResNet
오류를 3.6%까지 줄인 획기적인 방법입니다.
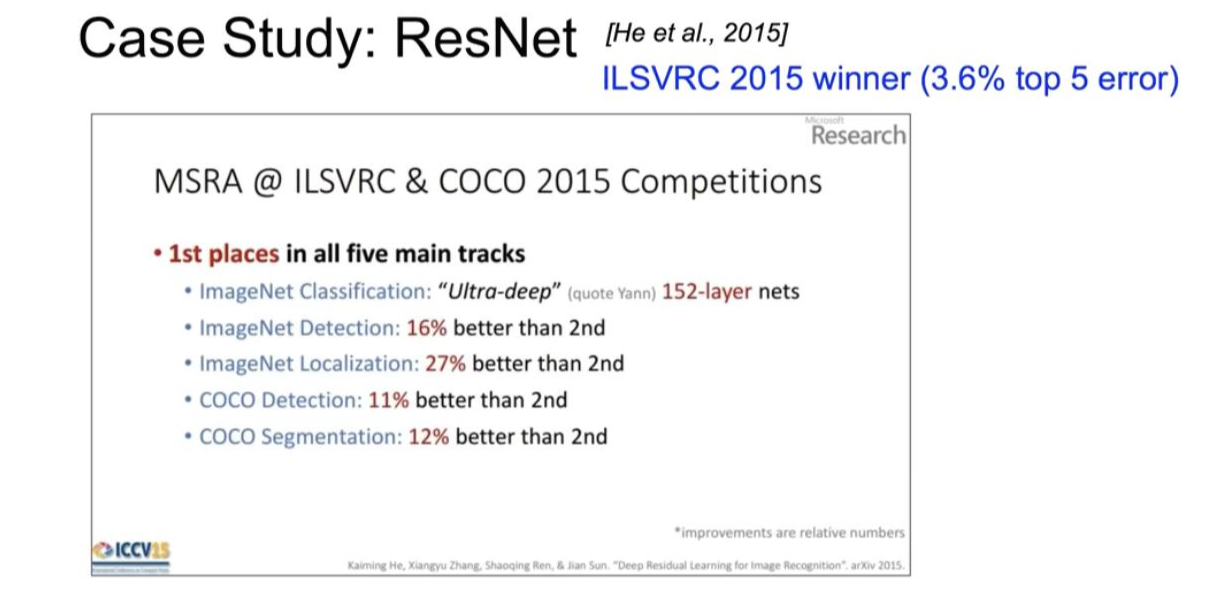

다른 Network들과 비교했을 때 굉장히 많은 수의 layer를 사용합니다. (192개의 layer 사용)

일반적인 경우에는 layer가 쭉 연결되어 있습니다. 그런데 ResNet의 경우에는 중간에 layer를 건너뛰고 앞의 layer와 연결됩니다.

중간에 layer를 건너뛰기 때문에, layer의 개수는 많지만 실제로 depth가 깊지 않은 느낌으로 학습이 가능합니다.

왼쪽의 ResNet과 오른쪽의 GoogLeNet Inception Module은 다른 형태이지만 상당히 비슷한 아이디어를 사용한 것이라고 볼 수 있습니다.
CNN을 활용한 이미지 외 또 다른 사례
1. 텍스트

이미지 뿐만 아니라 텍스트도 Convolution Neural Network로 처리해보았습니다.
2. 알파고

'인공지능' 카테고리의 다른 글
| [Keras] to_categorial 함수 (0) | 2021.02.19 |
|---|---|
| [모두를 위한 딥러닝1] NN의 꽃 RNN 이야기(8주차) (0) | 2021.02.17 |
| [모두를 위한 딥러닝1] Convolutional Neural Networks(CNN)(7주차_1) (0) | 2021.02.14 |
| [모두를 위한 딥러닝1] Weight의 초기값 설정하기(6주차_2) (0) | 2021.02.04 |
| [모두를 위한 딥러닝1] ReLU(6주차_1) (0) | 2021.02.04 |