ReLU의 등장 배경

layer가 높아질수록 앞쪽의 기울기를 알기 힘들어집니다.

지금까지 sigmoid를 잘못 사용하고 있었다는 것을 알게 되고 새로운 방법을 도입하게 됩니다.
ReLU(Rectified Linear Unit)의 등장

sigmoid는 항상 1보다 작은 값이므로, 이 값을 계속 곱해나가면 점점 작은 값이 됩니다.
그래서 1보다 큰 값을 사용하기 위해 등장한 것이 ReLU입니다. sigmoid가 사용되던 자리에 ReLU를 넣어줍니다.
L1=tf.sigmoid(tf.matmul(X, W1)+b1)
L1=tf.nn.relu(tf.matmul(X, W1)+b1)

ReLU를 이용해서 layer를 계속 거쳐 나갑니다. 그러나 마지막에는 0~1사이의 값으로 출력을 내야하기 때문에 sigmoid를 한 번 사용해줍니다.

tensorboard에서 ReLU가 사용되고 있다는 것을 확인할 수 있으며, accuracy는 시작할 때부터 1.0으로 높은 정확도를 가지고, cost 값도 급격하게 낮아지는 것을 볼 수 있습니다.

특히나 sigmoid를 사용했을 때와 비교해봤을 때 ReLU의 Cost 값이 급격히 빠르게 떨어지는 것을 확인할 수 있습니다.
다양한 Activation Functions

Leaky ReLU: 원래 ReLU값의 0인 부분을 살리기 위해 해당 값에 0.1을 곱하여 0보다 작은 지점을 약간 수정한 것입니다.
ELU: Leaky ReLU에서 앞에 0.1을 곱했었는데, 곱하는 값을 0.1로 고정하지 않고 변경해보는 것입니다.
Maxout: ReLU의 장점을 모두 가지고 있으면서 Dying ReLU 현상을 완전히 회복한 함수로, 성능이 가장 좋습니다.
tanh: sigmoid의 단점을 보완하여 값이 -1~1 사이가 되도록 한 것입니다.

정확도: maxout < ReLU < VLReLU < tanh < Sigmoid

입력값(fan_in)과 출력값(fan_out)에 비례하여 초기값을 조정합니다.
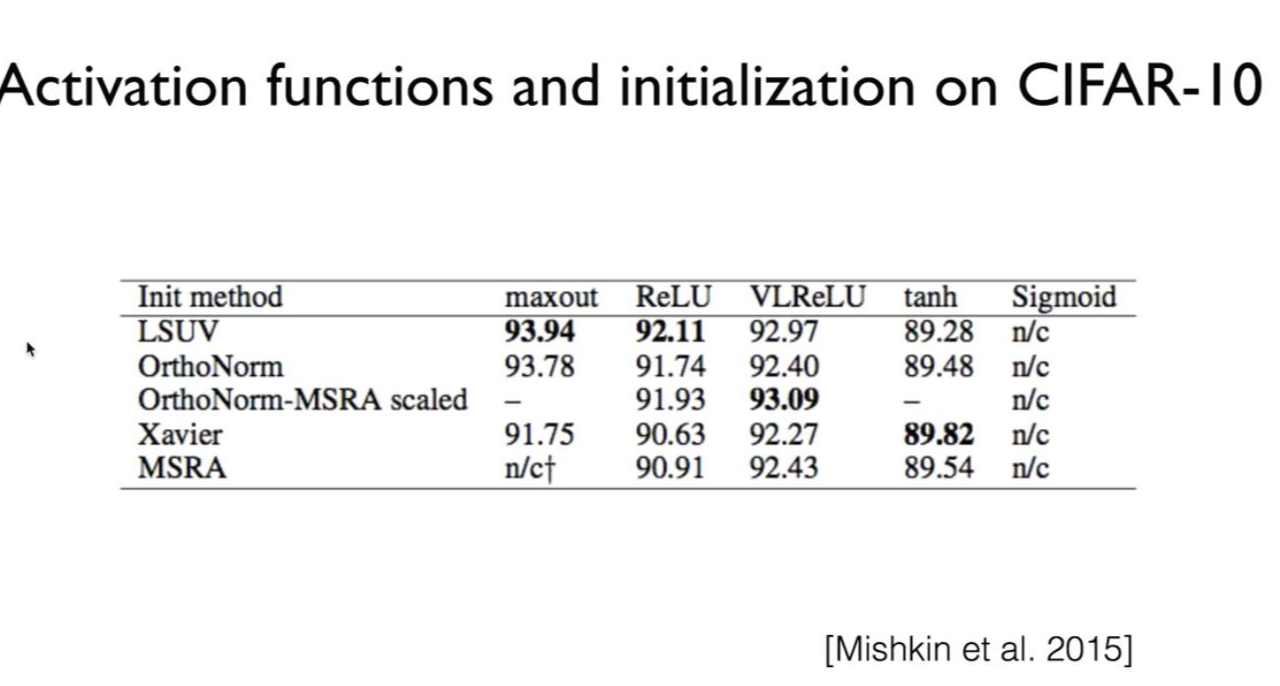
활성 함수별 초기값 조정하는 방법에 따른 차이
'인공지능' 카테고리의 다른 글
| [모두를 위한 딥러닝1] Convolutional Neural Networks(CNN)(7주차_1) (0) | 2021.02.14 |
|---|---|
| [모두를 위한 딥러닝1] Weight의 초기값 설정하기(6주차_2) (0) | 2021.02.04 |
| [모두를 위한 딥러닝1] 딥 네트워크 학습(5주차) (0) | 2021.01.27 |
| [Tensor Manipulation] Stack & Ones and Zeros like &Zip (0) | 2021.01.23 |
| [ 다차원 배열의 축] Axis (0) | 2021.01.23 |