Optimizer
loss function을 통해 구한 차이를 이용해 기울기를 구하고, network의 parameter(W, b)를 학습에 어떻게 반영할 것인지 결정하는 방법
Optimizer의 종류
Gradient Descent(GD)
-1회 학습 step시에 현재 모델의 모든 data에 대해서 예측 값에 대한 loss 미분을 learning rate만큼 보정해서 반영하는 방법
-gradient의 반대 방향으로 일정 크기만큼 이동해내는 것을 반복하여 Loss function의 값을 최소화하는 $\theta$의 값을 찾음

optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
Stochastic Gradient Descent(SGD)
-한번 step을 내딛을 때 전체 데이터에 대한 loss function을 계산하면 매우 느리므로 이를 방지하기 위한 방법
-일부의 data sample이 전체 data set 의 gradient와 유사할 것이라는 가정하게 일부에 대해서만 loss function 계산

optimizer = tf.keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False).minimize(cost)
Momentum
-이전 step의 방향(=관성)과 현재 상태의 gradient를 더해 현재 학습할 방향과 크기를 정함
-Local minima를 빠져 나올 수 있으므로 SGD의 Oscilation 현상이 해결 가능

Adagrad(Adaptive Gradient)
-Parameter 별로 gradient를 다르게 주는 방식
-많이 변화한 변수들은 G에 저장된 값이 커지기 때문에 step size가 작은 상태로, 적게 변화한 변수들은 상대적으로 step size가 큰 상태로 학습에 반영
-학습이 오래 진행되는 경우 G값이 너무 커져서 학습이 제대로 되지 않음

RMSProp
-학습이 오래 진행되면 step size가 너무 작아지는 adagrad의 단점을 보완하기 위한 방법
-각 변수에 대한 gradient의 제곱을 계속 더하는 것이 아니라, 지수평균으로 바꾸어 G값이 무한정 커지지 않도록 방지하면서 변화량의 상대적인 크기 차이를 유지

Adaptive Moment Estimation(Adam)
-Momentum 방식과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장
-RMSProp와 유사하게 지금까지 계산해온 기울기의 제곱값의 지수 평균을 저장
-학습 초반부에 m과 v가 0에 가깝게 bias되어 있을 것이라고 판단해 unbiased작업을 거친 후에 계산
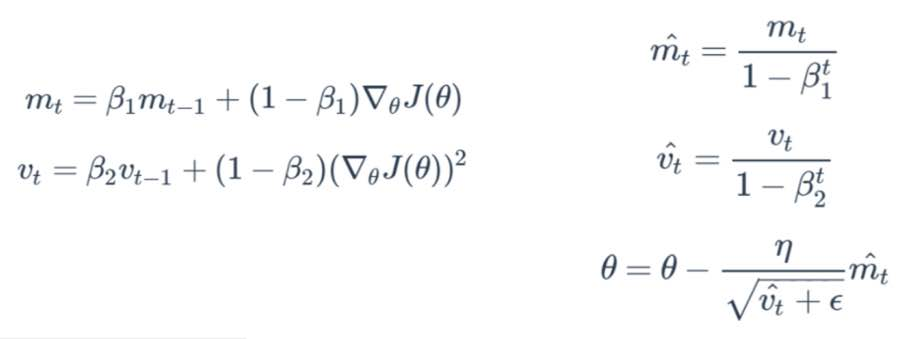
optimizer = tf.train.AdamOptimizer( learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam').minimize(cost)'인공지능' 카테고리의 다른 글
| [Tensor의 구조] Shape & Reshape (0) | 2021.01.20 |
|---|---|
| [Training Neural Network] epoch, batch, and iteration (0) | 2021.01.20 |
| [Keras] Keras에서 loss 함수 (0) | 2021.01.19 |
| [모두를 위한 딥러닝1] Soft classification(3주차) (0) | 2021.01.16 |
| [모두를 위한 딥러닝1] Logistic Regression (2주차) (0) | 2021.01.09 |